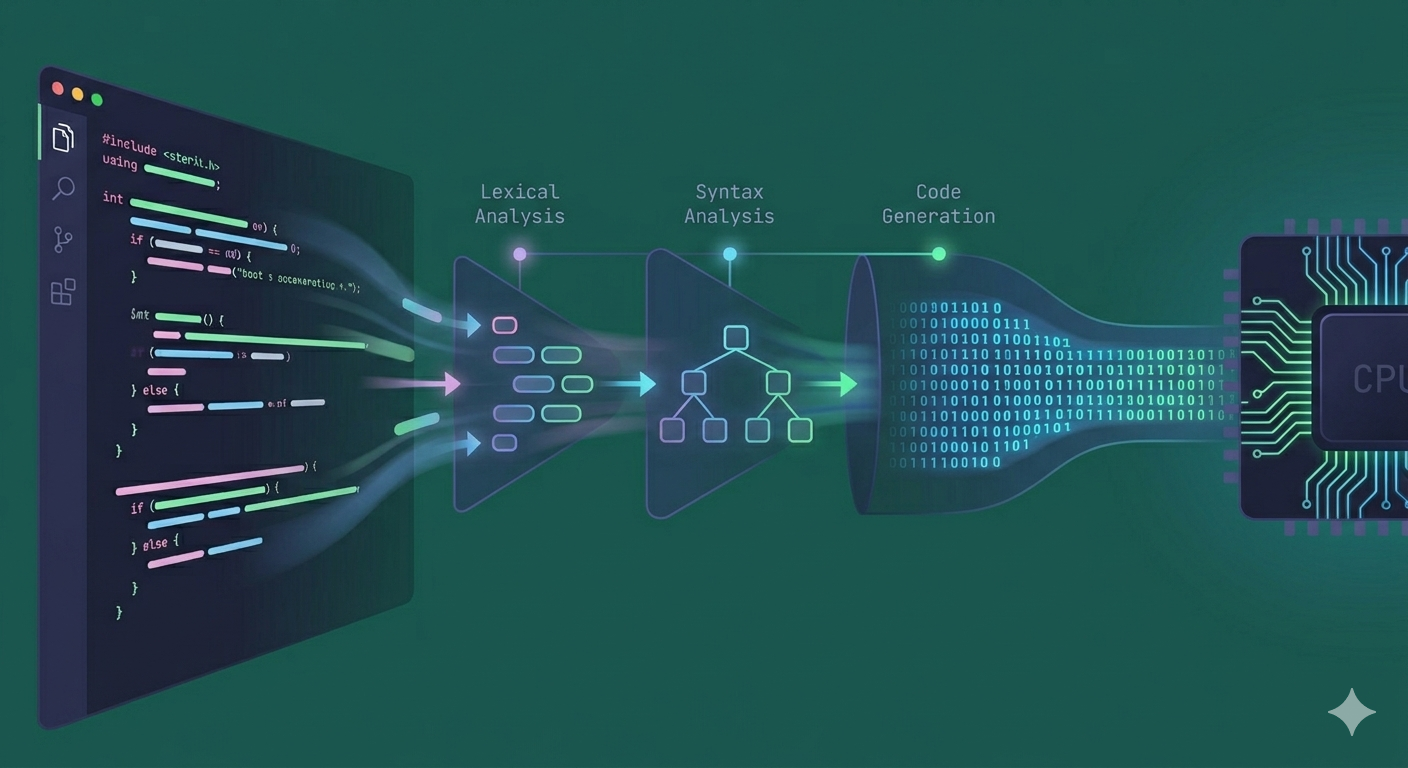
Every line of code you write — whether in C++, Rust, Go, or TypeScript — eventually becomes machine instructions that a processor executes. But the journey from human-readable source code to binary machine code is one of computer science's most sophisticated transformations. Modern compilers like GCC, LLVM, V8 (JavaScript), and Roslyn (C#) perform hundreds of complex analyses and optimizations to produce fast, secure, and efficient executables.
This post explores the internal architecture of modern compilers. We will trace the complete pipeline: lexical analysis (scanning), parsing (syntax analysis), semantic analysis, intermediate representation (IR) generation, optimization, and final code generation. We will also examine the difference between ahead-of-time (AOT) compilation used by C++ and just-in-time (JIT) compilation used by JavaScript and Java.
The Compilation Pipeline Overview
All traditional compilers follow a multi-stage pipeline. Each stage transforms the program representation, gradually moving from human-friendly text to machine-friendly bytes.
Source Code → Lexical Analysis → Parsing → Semantic Analysis →
IR Generation → Optimization → Code Generation → Machine Code
Modern compilers often repeat optimization stages and maintain multiple intermediate representations. LLVM, for example, uses over 20 different optimization passes on its IR before generating assembly.
Lexical Analysis: Tokenization
The first stage converts a raw string of characters into a sequence of tokens. Tokens are meaningful chunks: keywords (if, while, return), identifiers (count, total), literals (42, "hello"), operators (+, *, =), and punctuation (;, {, }).
The lexer (also called scanner or tokenizer) reads characters one by one, applying pattern matching rules. Most modern lexers use regular expressions or finite automata generated by tools like Lex, Flex, or handwritten recursive descent.
// Example source code
int sum = a + b * 10;
// Corresponding tokens
[KEYWORD_INT] "int"
[IDENTIFIER] "sum"
[OPERATOR_ASSIGN] "="
[IDENTIFIER] "a"
[OPERATOR_PLUS] "+"
[IDENTIFIER] "b"
[OPERATOR_MUL] "*"
[LITERAL_INT] "10"
[SEMICOLON] ";"
A simplified lexer implementation:
class Lexer {
constructor(source) {
this.source = source;
this.position = 0;
this.tokens = [];
}
tokenize() {
while (this.position < this.source.length) {
const char = this.source[this.position];
// Skip whitespace
if (/\s/.test(char)) {
this.position++;
continue;
}
// Match keywords and identifiers
if (/[a-zA-Z_]/.test(char)) {
let value = '';
while (this.position < this.source.length && /[a-zA-Z0-9_]/.test(this.source[this.position])) {
value += this.source[this.position];
this.position++;
}
const keywords = ['if', 'else', 'while', 'return', 'int', 'float'];
const type = keywords.includes(value) ? 'KEYWORD' : 'IDENTIFIER';
this.tokens.push({ type, value });
continue;
}
// Match numbers
if (/[0-9]/.test(char)) {
let value = '';
while (this.position < this.source.length && /[0-9]/.test(this.source[this.position])) {
value += this.source[this.position];
this.position++;
}
this.tokens.push({ type: 'NUMBER', value: parseInt(value) });
continue;
}
// Match operators
const operators = { '+': 'PLUS', '-': 'MINUS', '*': 'MULTIPLY', '/': 'DIVIDE', '=': 'ASSIGN' };
if (operators[char]) {
this.tokens.push({ type: operators[char], value: char });
this.position++;
continue;
}
// Match punctuation
if (char === ';') {
this.tokens.push({ type: 'SEMICOLON', value: ';' });
this.position++;
continue;
}
throw new Error(`Unexpected character: ${char}`);
}
return this.tokens;
}
}
Parsing: Syntax Analysis
The parser consumes tokens from the lexer and builds an Abstract Syntax Tree (AST) — a tree representation of the program's grammatical structure. Parsers verify that the token sequence follows the language's grammar rules (e.g., parentheses match, expressions are valid).
Most parsers fall into two categories:
Top-down parsers (recursive descent) start from the root grammar rule and recursively match productions. They are intuitive to write by hand and provide excellent error messages. Most production compilers use recursive descent with lookahead (LL parsing).
Bottom-up parsers start from the tokens and reduce them to grammar rules. They are more powerful but harder to debug. Yacc and Bison generate bottom-up parsers.
class Parser {
constructor(tokens) {
this.tokens = tokens;
this.position = 0;
}
peek() {
return this.tokens[this.position];
}
consume(expectedType) {
const token = this.peek();
if (!token || token.type !== expectedType) {
throw new Error(`Expected ${expectedType}, got ${token?.type}`);
}
this.position++;
return token;
}
// Grammar: program = statement*
parseProgram() {
const statements = [];
while (this.position < this.tokens.length) {
statements.push(this.parseStatement());
}
return { type: 'Program', statements };
}
// Grammar: statement = variableDeclaration | expressionStatement
parseStatement() {
if (this.peek().type === 'KEYWORD' && this.peek().value === 'int') {
return this.parseVariableDeclaration();
}
const expr = this.parseExpression();
this.consume('SEMICOLON');
return { type: 'ExpressionStatement', expression: expr };
}
// Grammar: variableDeclaration = 'int' IDENTIFIER '=' expression ';'
parseVariableDeclaration() {
this.consume('KEYWORD'); // 'int'
const name = this.consume('IDENTIFIER').value;
this.consume('ASSIGN');
const value = this.parseExpression();
this.consume('SEMICOLON');
return { type: 'VariableDeclaration', name, value };
}
// Grammar: expression = addition
parseExpression() {
return this.parseAddition();
}
// Grammar: addition = multiplication ('+' multiplication)*
parseAddition() {
let left = this.parseMultiplication();
while (this.peek()?.type === 'PLUS') {
this.consume('PLUS');
const right = this.parseMultiplication();
left = { type: 'BinaryExpression', operator: '+', left, right };
}
return left;
}
// Grammar: multiplication = primary ('*' primary)*
parseMultiplication() {
let left = this.parsePrimary();
while (this.peek()?.type === 'MULTIPLY') {
this.consume('MULTIPLY');
const right = this.parsePrimary();
left = { type: 'BinaryExpression', operator: '*', left, right };
}
return left;
}
// Grammar: primary = NUMBER | IDENTIFIER
parsePrimary() {
const token = this.peek();
if (token.type === 'NUMBER') {
this.consume('NUMBER');
return { type: 'NumberLiteral', value: token.value };
}
if (token.type === 'IDENTIFIER') {
this.consume('IDENTIFIER');
return { type: 'Identifier', name: token.value };
}
throw new Error(`Unexpected token: ${token.type}`);
}
}
For int sum = a + b * 10;, the parser generates this AST:
Program
└── VariableDeclaration (name: "sum")
└── BinaryExpression (operator: "+")
├── Identifier ("a")
└── BinaryExpression (operator: "*")
├── Identifier ("b")
└── NumberLiteral (10)
Semantic Analysis
Parsing verifies syntax but not meaning. Semantic analysis checks that the program makes sense: variables are defined before use, types are compatible, functions exist, and scopes are respected. This stage typically uses symbol tables and type checking.
class SemanticAnalyzer {
constructor() {
this.symbolTable = new Map(); // name → { type, kind }
this.errors = [];
}
analyze(node) {
if (node.type === 'Program') {
for (const stmt of node.statements) {
this.analyze(stmt);
}
}
if (node.type === 'VariableDeclaration') {
// Check if variable already declared in current scope
if (this.symbolTable.has(node.name)) {
this.errors.push(`Variable '${node.name}' already declared`);
}
// Analyze initializer expression
const valueType = this.analyzeExpression(node.value);
// Type checking (int = int)
if (valueType !== 'int') {
this.errors.push(`Cannot initialize int with ${valueType}`);
}
this.symbolTable.set(node.name, { type: 'int', kind: 'variable' });
return 'int';
}
if (node.type === 'ExpressionStatement') {
return this.analyzeExpression(node.expression);
}
}
analyzeExpression(expr) {
if (expr.type === 'NumberLiteral') {
return 'int';
}
if (expr.type === 'Identifier') {
if (!this.symbolTable.has(expr.name)) {
this.errors.push(`Variable '${expr.name}' not declared`);
return 'unknown';
}
return this.symbolTable.get(expr.name).type;
}
if (expr.type === 'BinaryExpression') {
const leftType = this.analyzeExpression(expr.left);
const rightType = this.analyzeExpression(expr.right);
if (leftType !== 'int' || rightType !== 'int') {
this.errors.push(`Binary operator ${expr.operator} requires integers`);
}
return 'int';
}
}
}
After semantic analysis, compilers convert the AST into an Intermediate Representation (IR). IR is platform-agnostic, simpler than source code, and optimized for analysis and transformation. LLVM's IR is the industry gold standard.
LLVM IR example for sum = a + b * 10:
; LLVM IR
define i32 @compute(i32 %a, i32 %b) {
entry:
%mul = mul i32 %b, 10
%sum = add i32 %a, %mul
ret i32 %sum
}
IR provides several advantages:
-
Single Static Assignment (SSA) form means each variable is assigned exactly once. This simplifies optimizations because data flow is explicit.
-
Infinite virtual registers free compilers from hardware constraints during optimization.
-
Explicit control flow using basic blocks and branch instructions.
Optimization
Optimization is where modern compilers distinguish themselves. Over 50-70% of a compiler's code handles optimization. Transformations run repeatedly, each improving the program's speed, size, or power consumption.
Constant Folding
Compute constant expressions at compile time instead of runtime:
// Before optimization
x = 5 * 3 + 2 * 4
// After constant folding
x = 23
Constant Propagation
Replace variable references with known constant values:
// Before
const int x = 42;
int y = x + 10;
// After
int y = 52; // x eliminated
Dead Code Elimination
Remove code that never executes or whose results are never used:
// Before
int x = 10;
int y = 20;
if (false) {
printf("Never runs");
}
return x;
// After
int x = 10;
return x; // y and if-block removed
Loop Optimization
Loop unrolling duplicates loop bodies to reduce overhead:
// Before
for (int i = 0; i < 4; i++) {
arr[i] *= 2;
}
// After (unrolled)
arr[0] *= 2;
arr[1] *= 2;
arr[2] *= 2;
arr[3] *= 2;
Loop invariant code motion hoists calculations that don't change:
// Before
for (int i = 0; i < n; i++) {
arr[i] = arr[i] + sqrt(x) * 2; // sqrt(x)*2 computed 1000x
}
// After
const int factor = sqrt(x) * 2; // Computed once
for (int i = 0; i < n; i++) {
arr[i] = arr[i] + factor;
}
Inlining
Replace function calls with the function body:
// Before
int square(int x) { return x * x; }
int result = square(5) + square(6);
// After (inlined)
int result = (5 * 5) + (6 * 6);
GCC and Clang have over 200 optimization flags. -O2 (standard optimizations) and -O3 (aggressive optimizations) enable different optimization passes.
Code Generation
The final stage converts optimized IR into machine code for a specific architecture (x86-64, ARM, RISC-V). Code generation involves:
Instruction selection maps IR operations to CPU instructions:
; LLVM IR
%sum = add i32 %a, %b
; x86-64 assembly
add eax, ebx
; ARM64 assembly
add w0, w0, w1
Register allocation assigns IR virtual registers to physical CPU registers (x86-64 has 16, ARM64 has 31). Spilling moves values to memory when registers are exhausted.
Instruction scheduling reorders instructions to avoid pipeline stalls:
; Suboptimal (stalls on multiply)
mov eax, [memory]
imul eax, 5
add eax, ebx
mov [result], eax
; Better (independent work during multiply)
mov eax, [memory]
mov ecx, ebx ; Work while multiply runs
imul eax, 5
add eax, ecx
mov [result], eax
AOT vs JIT Compilation
Ahead-of-Time (AOT) compilation (C, C++, Rust, Go) translates all code to machine instructions before execution. Benefits: fast startup, no runtime overhead, predictable performance. Drawbacks: longer build times, platform-specific binaries, harder optimization (unknown runtime data).
Just-in-Time (JIT) compilation (JavaScript, Java, C#) compiles code at runtime, typically in stages:
// V8 JavaScript engine pipeline (simplified)
Source Code → Parser → AST → Ignition (Interpreter) →
Bytecode → Execution → Profiling → Hot Code → TurboFan (Optimizing JIT) →
Optimized Machine Code
// Cold code (executes once) stays interpreted
function rarelyUsed() { return 1 + 1; }
// Hot code (executes many times) gets optimized
for (let i = 0; i < 1000000; i++) {
sum += Math.sqrt(i); // sqrt becomes optimized machine code
}
V8's TurboFan compiler uses speculative optimization — it assumes observed types will continue:
// V8 sees: add is always integers
function add(a, b) {
return a + b;
}
// Optimized version assumes integer addition
// If a string appears later, deoptimization occurs (slower)
JIT advantages: profile-guided optimization (optimize hot paths based on actual usage), cross-platform (same bytecode runs everywhere), runtime code generation. Disadvantages: warmup time (code gets faster over time), memory overhead, security risks (executable memory pages).
Tiered Compilation in Java (HotSpot JVM)
Java Source → javac → Bytecode (.class) → Interpreter →
C1 Compiler (fast, low optimization) → Profile Collection →
C2 Compiler (slow, aggressive optimization) → Native Code
Real-World Compiler Architecture: LLVM
LLVM is the most successful modern compiler infrastructure. Its three-phase design separates frontend, optimizer, and backend:
Clang (C++ Frontend) → LLVM IR → Optimizer (30+ passes) →
LLVM IR → X86 Backend → Machine Code
→ ARM Backend → Machine Code
→ WebAssembly → .wasm
This design allows LLVM to support 40+ frontends (Clang for C/C++, rustc for Rust, flang for Fortran, etc.) and 20+ backends (x86, ARM, RISC-V, WebAssembly, SPARC, etc.).
How JavaScript Works: A Case Study
JavaScript is neither purely compiled nor purely interpreted. Modern engines use multiple execution tiers:
Parser generates AST and scopes.
Ignition (interpreter) generates bytecode and executes it. This fast startup gets code running immediately.
Profiler watches executing bytecode, counting operations and tracking types.
TurboFan (optimizing compiler) recompiles hot functions to optimized machine code using speculative assumptions.
Deoptimization rolls back to interpreter when assumptions break.
// Example: function becomes hot and gets optimized
function addVectors(a, b) {
return { x: a.x + b.x, y: a.y + b.y };
}
// Called 10,000+ times with Vector objects
// TurboFan speculatively optimizes for Vector
for (let i = 0; i < 100000; i++) {
result = addVectors(vec1, vec2);
}
// If a different type appears, deoptimization occurs
addVectors(1, 2); // Triggers deoptimization back to interpreter
Final Thoughts
Modern compilers are among the most complex software systems ever built. GCC has over 15 million lines of code. LLVM exceeds 10 million. Each stage — lexical analysis, parsing, semantic analysis, IR generation, optimization, code generation — contains decades of research and engineering.
Understanding compilers makes you a better programmer. You write loop invariant code because you know compilers hoist it. You use local variables because you know register allocation prefers them. You understand that JavaScript's performance varies because of JIT compilation tiers and deoptimization.
The next time you run gcc main.c or node app.js, remember: you are witnessing one of computer science's greatest achievements — the automatic transformation of human logic into machine execution, billions of times per second, on billions of devices worldwide.